直していたというか、退職に伴いブログ環境をプライベートのマシンに入れる作業を 中途半端にこなしていたという次第でして…
(なので平日限定だったのですw)
というわけで、新しい職場で働いてもうすぐ4ヶ月が経過しようとしていますが、 割と元気にやっております。
大阪Pythonユーザの集まりも 2回活動しましたし(といっても1つは忘年会)。 来年もまた活動しますよ!
その辺も踏まえた報告はまた次のポストにでも書きますね…。
直していたというか、退職に伴いブログ環境をプライベートのマシンに入れる作業を 中途半端にこなしていたという次第でして…
(なので平日限定だったのですw)
というわけで、新しい職場で働いてもうすぐ4ヶ月が経過しようとしていますが、 割と元気にやっております。
大阪Pythonユーザの集まりも 2回活動しましたし(といっても1つは忘年会)。 来年もまた活動しますよ!
その辺も踏まえた報告はまた次のポストにでも書きますね…。
8月31日をもって、株式会社ラクスを退職しました。29日が最終出社日です。 入社は2012年3月1日ですので、2年半お世話になりました。
入社してからというもの、Rignite という ソーシャルメディアマーケティング用Webサービスの開発に従事しておりました。
技術的にも色々なものに触れることができました。 トピックだけでも書くと…何と言いますか、特殊なことばっかりやっていた気がします。 それもこれも、チームのメンバーに恵まれた結果かなと思っています。
一方、自分が技術だけに突き進んでいいのか?という気持ちも湧いてきており、 もっとチーム力の底上げをしていく仕事もしたいと思うようになりました。 そして将来的には、経営とITを融合させるためにはどうすればいいかを、考え実践していく…
そう考えたとき、今のポジションは適切ではないのだろう、と考えてしまったわけです。
というわけで、早速来週9月1日から、新たな会社で新たなポジションとして、 心機一転、頑張っていく所存であります! 結局技術もバリバリやりますけどね!
※時間切れでコレ以上書けない…
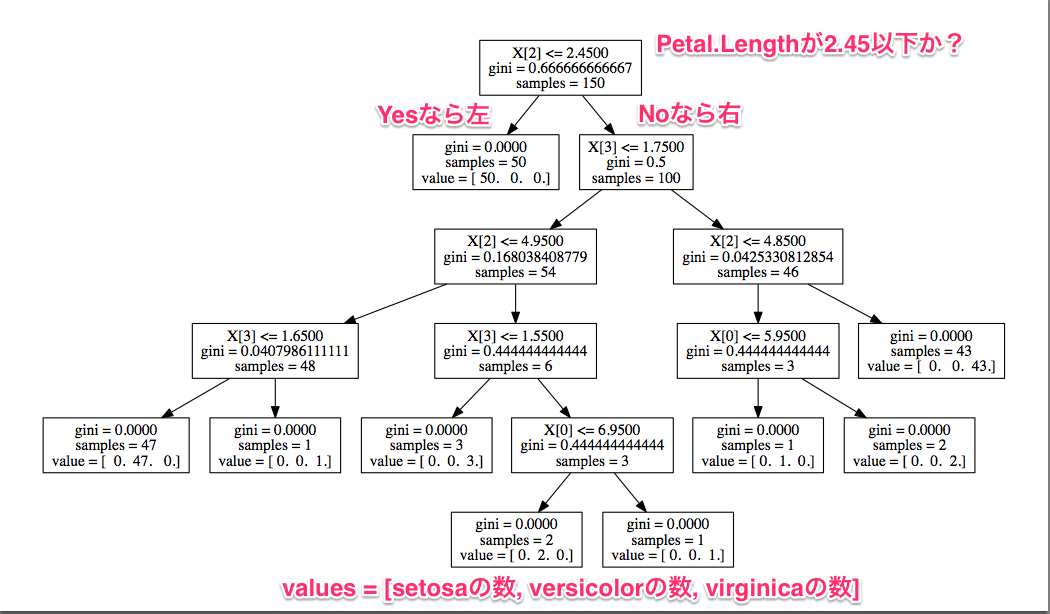
決定木を描画できたのはいいのですが、「変数が0数えで何番目かをいちいち数えなきゃいけないのが不便!」 というお声をいただきまして、早速調査しました。
結論から言いますと、できました。
sklearn.tree.export_graphviz
関数の引数に、feature_namesを渡せばよかったです。
変更後のプログラムはこちら。export_graphviz関数の引数に、feature_names=variablesを渡しています。
1 2 3 4 5 6 7 8 9 10 11 | |
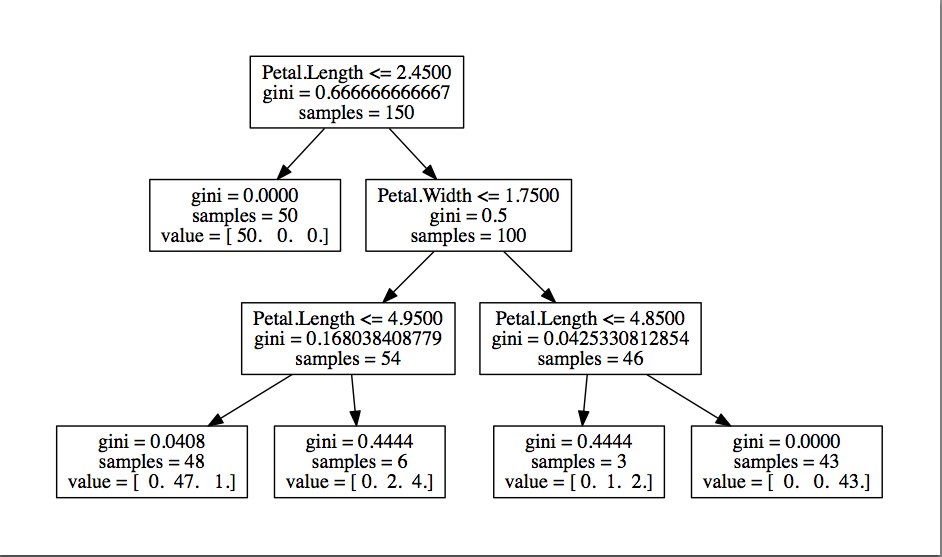
結果得られた決定木はこちら。非常に見やすくなりました!
データ分析が必要な局面がぼちぼち出てきましたので、まずは簡単な決定木を用いて 分析結果の可視化をしようじゃないか、というのが今回の目論見です。
決定木とは、scikit-learnの1.8. Decision Treesによると、 分類や回帰を行うために使われる、ノンパラメトリックな教師あり学習のひとつ、とあります。 また、目的は、学習データ中の特徴(説明変数)を用いて、目的変数の推測を行えるモデルを作ること、だそうです。
ナンノコッチャ?ですので例を挙げますと、例えばある有料サービスに申し込んでくれる人を増やすために、 今までの履歴からどういったお客様が有料サービスに申し込んでくれたか、を調査するとします。 無料サービスA, B, Cがあったとして、どれとどれをどのくらい使っている人が 有料サービスを申し込んでくれるか、こういうことを考えたいわけですね。 ここで言う無料サービスA, B, Cが説明変数で、有料サービスに申し込むかどうかが目的変数になります。
決定木を使うことにより、Aのサービスを10回使って、かつCのサービスを1回以上使ったお客様は 有料サービスを申し込んでくれる可能性が高い、というモデルを構築することが出来ます。 また、モデルが構築できたら、そのモデルを用いて、有料サービスを申し込む前から 今までの行動から、お客様が有料サービスに申し込んでくれるかどうかを推定することができるようになるわけです。
brew install graphvizでOK)まずは自分の分析したいデータを用意します。…といっても、すぐに用意できないことがあるかと思いますので、 こちらに事前に調理しておいた…いやいや、日本語解説付きのデータセットがありますので、 気になるデータを使用してみてください。 統計を学びたい人へ贈る、統計解析に使えるデータセットまとめ
ここでは、Irisデータを使用します。
データの読み込み・選定あたりでpandasを使用し、実際の学習でscikit-learnを使用します。
下記のようなコードを書き、実行してください。
graph.dotというファイルが生成されます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
上記のコードより得られる結果は graph.dot というファイルなのですが、
これだけ見てもよく分かりません。
そこで、下記コマンドを実行し、PDF変換します。
1
| |
結果を見てみましょう。
見方は、上から順番に、説明変数を0から数えて2番め(Petal.Length)が2.45以下か
否かで、Yesなら左、Noなら右に進んでいくことで分類していきます。
Yesならsetosa全データが入っているので、これは分類が容易だと分かります。
Noなら、次はPetal.Widthが1.75以下か否かで…というかたちで見ていけばよいです。
決定木は分類ルールが生成されるので、人にとっても解釈しやすいですね。
ところで今回得られた結果には、大きな問題が2つあります。 ひとつは、未知のデータに対しても有効かどうかが分かりません。 もうひとつは、過学習している可能性が高いことです。
過学習とは、与えられた学習データにフィットしすぎた結果、
未知のデータに対して正しい分類ができない状態のことです。
今回の決定木も、非常に細かいところまで分類しています。
例えばPetal.Width <= 1.75のとき、90%の確率でversicolorになるはずなのですが、
その条件下でPetal.Width > 1.65のときはvirginicaである、と分類しています。
要するに、1.65 < Petal.Width <= 1.75のときはvirginicaである、という
細かい分類をしてしまうわけです。
この結果は確かに与えられた学習データに対してはうまくいきますが、
未知のデータに対しては、分類が細かすぎて誤分類してしまう可能性が高まります。
そこで、分類データを何個かに分割して、大部分を決定木の作成に使用し、 残る一部のデータを、その決定木の性能測定に使用します。 この操作を「交差検定 (Cross-validation)」と言います。
早速交差検定をやってみましょう。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
結果は下記のように出力されます(データセットを本プログラム起動時にシャッフルしているため、 結果は常に異なった値になります)。 この場合、94.67%の精度で分類ができていることになります。何となく良さげな精度?ですが、 100個のデータを与えたら、5〜6個は間違えるよ、という精度ですね。
1
| |
決定木の過学習を抑える対策は、大きく分けて2つあります。
1.の方は、先ほどのPetal.Widthの例を防ぐ事ができるようになります。
本設定を使用するには、tree.DecisionTreeClassifierのコンストラクタ引数で設定を入れましょう。
1
| |
2.の方の設定は、下記のように行います。 ルートノードを0として、子ノードまでが1、孫ノードまでが2…と設定します。
1
| |
そして、2つのパラメーターをどう設定するのが良いか…これはもう計算してもらいましょう。
min_samples_leafを1〜7、max_depthを2〜8、それぞれの組み合わせで精度を計算します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
結果はこちら。平均精度、min_samples_leaf、max_depthの順番です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
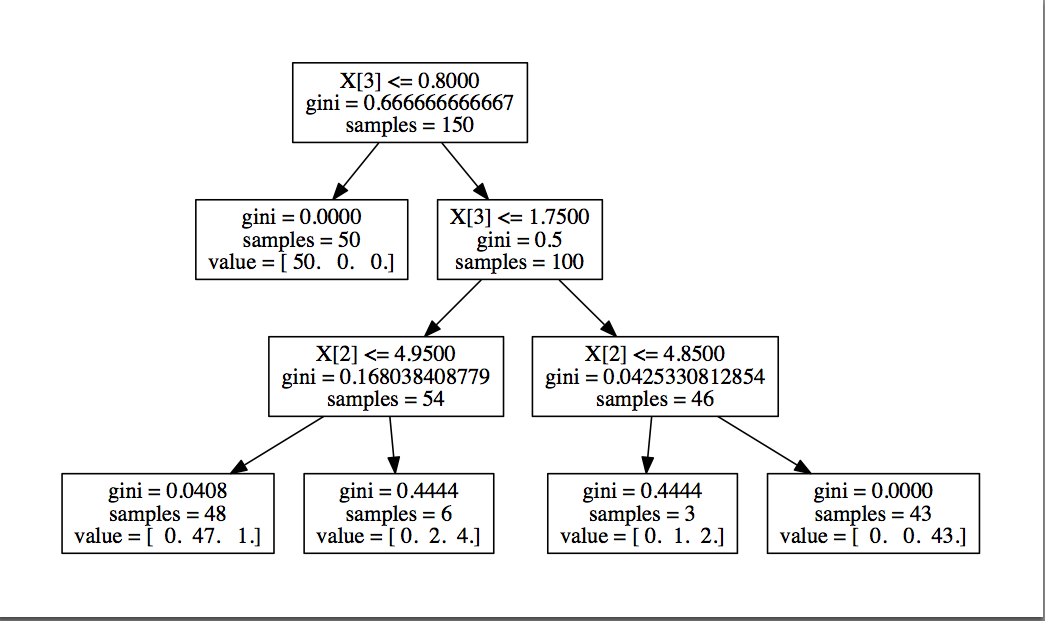
100個のデータを与えたら6個間違えるパラメーター未設定時と比較し、最良の場合は
100個のデータを与えたら3〜4個間違える程度まで軽減されました。
ちなみにmin_samples_leaf=3, max_depth=3のときの決定木はこちら。
ちなみに、パラメーターの調整には、scikit-learnにGrid Searchなる機能があり、 各種パラメーターを入れ替えながら検証してくれる仕組みがあります。 今回は使いませんでしたが、次回試してみるつもりです。
Python + pandas + scikit-learn で決定木を計算する方法をご紹介しました。 また、精度の計算に交差検定を使う方法と、決定木で過学習を抑えるための方法をご紹介しました。
実際のデータに対して試してみると、思わぬ発見が出てきて楽しいですよ。 是非お試しください。
Oracle Java の脆弱性対策について(CVE-2014-4227等) のアナウンスと共に、本脆弱性に対する修正プログラムがリリースされましたね。 ※実際には修正プログラムが出る前に、脆弱性の報告が上がってしまって肝を冷やしましたが…
さて自分の開発環境のMacでもJDK 8 Update 11をインストールしたわけですが、
インストール後にjava -version と打っても、今まで使っていたバージョン情報しか出なかったわけで、少し焦りました。
原因は、分かってしまえば何てことはなく、環境変数 JAVA_HOME の書き換えを忘れていた、というオチでした。
というわけで、環境変数を下記のように書き換えればOK。
1
| |
確認します。
1 2 3 4 | |
無事にバージョン切り替え完了!
またQiita側への投稿ですが、こちらにもリンクを載せておきます。
IntelliJ IDEAでGitのRevision Graphを見る – Qiita
さりげなく未だにSubversionを使ってるアピールも欠かさないわけで、切ないですね。 もっと気軽にブランチを切りたいです。。
オープンソースのプロジェクトについて、リリース情報を収集して一覧するサービスを作っています。 その名もOSS Release Checkerという、いかにも日本人が付けたような名前です。
http://osschecker.appspot.com/
うちの会社の業務で、ライブラリやフレームワークのリリース情報をチェックして報告する業務があります。 それ毎日見るの面倒だからリリース情報のチェックを一手に引き受けてくれるサービスを作ったらえぇやん、というのが発想ですね。
機能的な話ですが、まずはリリース情報の収集先はGitHubをターゲットにしています。 検索画面から気になるプロジェクトを検索してウォッチしていけば、あとは自動的にリリース情報を収集してくれます。 そして収集した結果、最新のリリースおよびタグ付けされたリポジトリが、画面に一覧表示される、という寸法です。
直近の目標はこんな感じです。 GitHubのアカウントでOAuthした上で、自分のウォッチしたいリポジトリを登録しておきます。 そして、ウォッチしているリポジトリに更新があればGitHubのメールアドレスに対してメール通知すると。 これができたら、自分的にはいい感じですね。
あとは見た目はもう少し何とかしたいですね。検索画面とか、Bootstrap感満載の画面とか…。 ドメインを取ってみたもののApp Engineに適用しようと思ったらGoogle Appsが必要みたいで躊躇してたり… (Google Appsが必要じゃないケースもあるらしいが…)
最後に、GitHubで何かしら開発されている方は、タグ付けだけでなく、GitHubのリリース機能を使用してください。 リリース機能を使うことで、ただのタグ付けだけでなく、そのリリースがどういうものかを説明する場所と、モジュールの配布場所が提供されます。 そして、私のサービスでも、リリース情報として取り込むことができるようになります。
※ GitHubのリリース機能を使う – Qiita も 合わせてご参照ください。
こちらからは以上です。
何度かハマるので、メモ的に書いておきました。
npm installでpeerinvalidエラーが出た時の解消方法
ところで、今作っているサービスのデプロイの際に、npmからモジュールを都度取ってきて 処理を行う的な部分があるのですが、npmに上がっているモジュールに問題があった場合に デプロイの処理が止まってしまう問題があります。 対策としてはnpmに上がっているモジュールのバージョンを固定にしてしまうことだとは 思うのですが、一方で開発の際には、なるべく最新のモジュールを使うべく、 このバージョン以降を使う、という設定をしています(Qiitaに載せてるpackage.jsonみたいに)。
ローカル開発環境と、ステージング&本番環境では、package.jsonの管理方法を変えるのが良いか、 はたまたどちらも統一してしまうべきか、少々悩ましいです。
皆様がどうされているのか、教えていただければ嬉しいですね。
GitHubにRelease機能というのがあります。 個人的にすごく好きな機能の一つなのですが、あまり使われていない模様でしたので、 Qiitaに GitHubのリリース機能を使う – Qiita を投稿しました。
例えば同僚が作っている intercom-javaのreleases を見ると、 ただタグを打っただけではなく、そのリリースに何が含まれているかが書かれており、 リリースの内容が即座に分かって、非常にいいと思うんですね。
特にリリース内容もアップロードできますので、 Goでツールを作ってクロスプラットフォーム用バイナリを生成した場合には、 Release機能を使ってバイナリもアップロードすれば、配布の手間が省けて便利になります。
ちなみに私がGitHubのRelease機能を推しているのにはもうひとつ理由がありまして…。 その理由は、また近いうちに書きますね。
大阪Pythonユーザの集まりの勉強会、 大阪Pythonユーザの集まり 2014/05の 企画、参加、発表してきました。
まさか開始前に、高専談義が行われるとは…(私含め3名の高専出身者が参加されていました)。
増田さん (@whosaysni) による、 Djangoを使う上での黒魔術的な工夫。 Djangoは触ったことがなかったので、黒魔術自体は参考になることはなかったものの、 内部実装を交えた話があることで、ずいぶんと興味深く聞くことができた。 スコープがスタックとして実装されており、上から順番に探索しているので、 ネストした名前の解決もうまくいくと。
オープンCAE勉強会@関西幹事の片山さんによる、 オープンCAEに関する実装とPythonとの関連について。 CAEとはCAE – Wikipediaによると、
コンピュータ技術を活用して製品の設計、製造や工程設計の事前検討の支援を行うこと、またはそれを行うツールである
とのこと。 今回は、数値解析・シミュレーションなどで使われる計算を行うソフトウェアの オープンソース実装と、Pythonがどのように関係しているかをご紹介いただいた。 今回ご紹介いただいたオープンソース実装には何かしらPythonのインターフェースがあり、 最終的には、これらの実装をPythonでつなぐことを検討中とのことです。
私の発表です。知らぬ間にPython 2.7を使っており、int / int でfloatが返ってきてハマった話から、 Python 2でも3でもコードをメンテナンスしなければならない場合の、 取りうる戦略とメリット・デメリットについて発表しました。
会津さん (@Ido) による、瞬間的な大量リクエスト(スパイク)を App Engineでどのように捌くかについて。 あるインスタンスが1秒間に捌けるリクエスト数から、予想される最大リクエスト数に対する インスタンスを事前に起動しておくことで対処する。 4桁台のインスタンスを起動する的な話も…これはApp Engineならではと言った感じですね。
http://www.hexacosa.net/documents/osakapy-20140529-lt
服部さん (@hhatto) による、 ソーシャルゲーム開発・運用周りで作ったツールの紹介。 あちこちで使われており、自分もまだまだ業務改善する余地がありそうだなぁと反省…。
実は当日までお店すら決めていなかったのです。 今回は参加人数も多くないし、大丈夫だろうと高をくくっていたのですが、 蓋を開けると勉強会参加者は20名、懇親会参加者も11名に。
当日のお昼に急いで店を探して予約して、飲み放題プランで料金3500円ポッキリ、 当日の参加もOKよ!というかたちにしました。
また、前回は自分の終電の都合もあって23時解散にしたのですが、 もう少しゆっくりしたい方々もいらっしゃるかもしれないと思い、 実際の会計は増田さんにお願いしました。増田さん、ありがとうございます。
懇親会では、Javaのコミュニティの大移動の話や、フリーランスとしての活動の話など、 Python以外にも色々ためになる話を聞くことが出来ました。 そしてまた今回もErlangいいよ、という話が聞こえてきたので、 そろそろErlangを真面目に触ってみたほうがよいのかも…(いやいやそんな時間ないわ…)。
まだ未定ですが、多分勉強会は8月開催だと思います。 また、数時間程度のハッカソンは別途検討したいと考えています。 土日の合宿もやってみたいですが、まずは平日のハッカソンかなぁ…。